Co to jest robot internetowy?
Robot internetowy (znany też pod nazwami crawler, spider, bot, pełzacz, web wanderer), to oprogramowanie stworzone do systematycznego przeglądania stron internetowych i wykonywania określonych, powtarzalnych zadań.
To, w jaki sposób się poruszają i co rejestrują boty internetowe, w dużej mierze wpływa na pozycjonowanie stron internetowych. Ponadto eksplorowanie Internetu za pomocą programów komputerowych ułatwia i znacznie przyspiesza segregowanie witryn oraz zbieranie informacji na ich temat. Warto przy tym zaznaczyć, że ponad połowa ruchu generowanego w sieci to sprawa botów internetowych. Popraw skuteczność swojej strony internetowej – zamów audyt SEO od ekspertów!
Boty internetowe można podzielić na „dobre” oraz „złe”. Pierwsza grupa zajmuje się zarówno gromadzeniem informacji o strukturze oraz treści, jak i wyszukiwaniem duplikatów tych treści – przykład: bot dedykowany platformie YouTube odnajduje kopie utworzone bez wiedzy właściciela oryginalnej treści. Inna grupa robotów internetowych może z kolei namieszać w prawidłowym funkcjonowaniu witryny, np. spowalniając jej działanie wskutek pobierania zbyt dużej ilości treści z danej strony.
Do grupy „dobrych” robotów, z którymi możemy zetknąć się najczęściej, należą:
- feed fetcher – bot, który pobiera wiadomości ze stron internetowych do wyświetlania w aplikacjach mobilnych, takich jak np. Wiadomości Google,
- boty komercyjne stosowane jako narzędzia marketingu cyfrowego,
- boty monitorujące prawidłowe funkcjonowanie strony internetowej,
- boty indeksujące, które zbierają dane wykorzystywane do tworzenia indeksów stron internetowych.
Pod kątem pozycjonowania stron internetowych najistotniejsze są dla nas roboty indeksujące, działające dla wyszukiwarki Google.
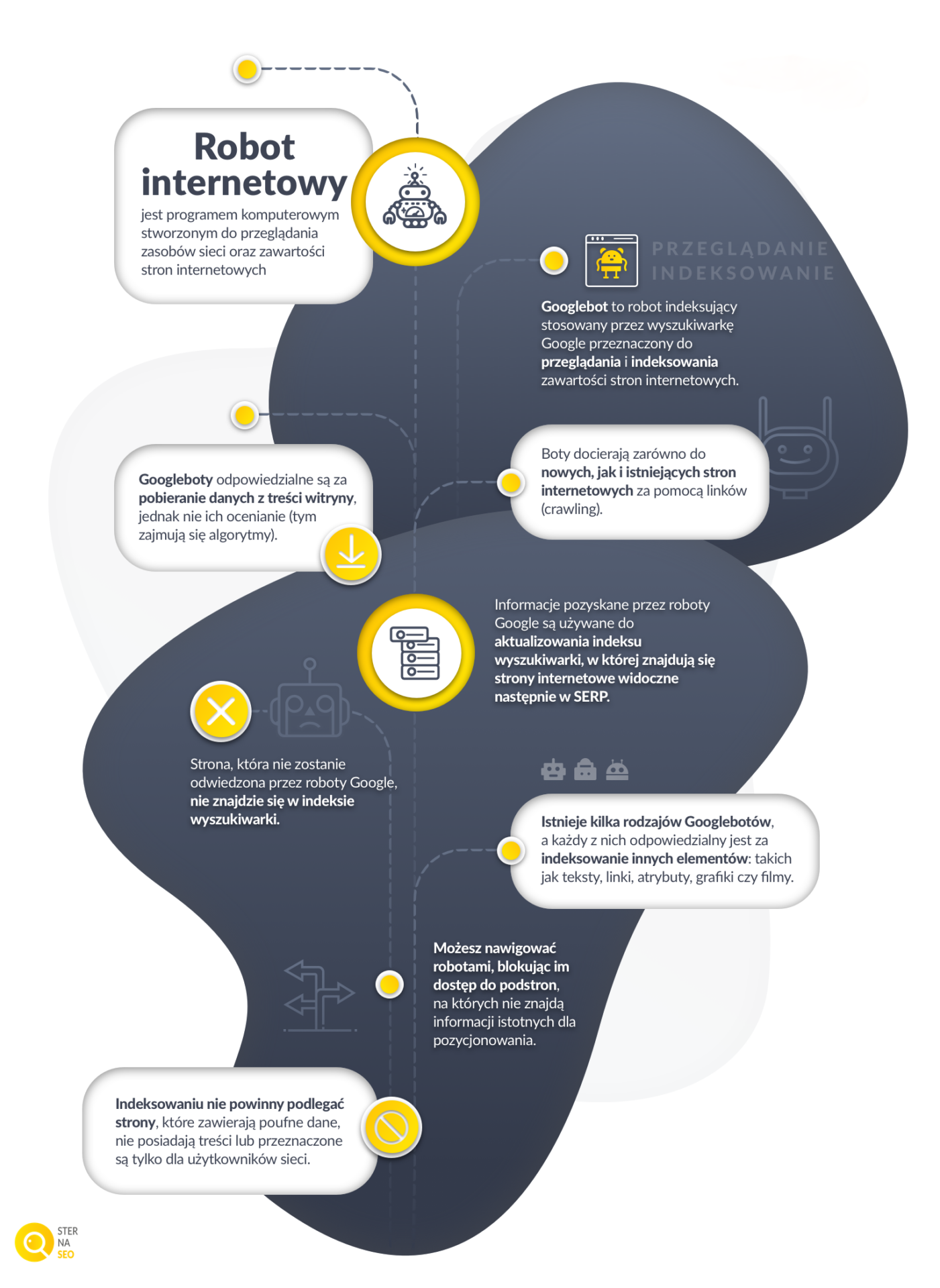
Googlebot
Czym jest Googlebot?
Googlebot to rodzaj bota internetowego, którego zadaniem jest indeksowanie stron internetowych. Boty pobierają, przetwarzają oraz zbierają informacje o ich zawartości, a następnie zapisują je i porządkują w bazie danych tworzonej przez wyszukiwarkę Google. Dane te są następnie wykorzystywane przez algorytmy wyszukiwarki do tworzenia rankingu wyników wyszukiwania.
Roboty Google przemieszczają się z witryny na witrynę za sprawą linków (proces ten nazywany jest crawlingiem lub skanowaniem). W ten sposób mogą w krótkim czasie pobrać całe mnóstwo gigabajtów danych, które trafiają następnie do indeksu (ten proces jest z kolei indeksowaniem). Aby indeks był stale poszerzany, Google właściwie nieustannie przeszukuje sieć w poszukiwaniu aktualnych informacji.
Możliwe jest także nawigowanie robotami indeksującymi: za pomocą mapy witryny oraz pliku robots.txt.
Indeksowanie to dodawanie strony internetowej do indeksu, na podstawie którego tworzony jest ranking wyszukiwarki – o czym więcej dowiedziałeś się z naszego poprzedniego artykułu Indeksowanie strony: definicja i podstawy.
Roboty wyszukiwarki Google generują spory ruch w Internecie – mówiąc o robotach indeksujących wspominamy więc przede wszystkim o Googlebotach. To właśnie dzięki ich skrupulatności witryna pojawia się w indeksie.
Jak działa Google bot?
Za sprawą crawlingu Googlebot przechodzi z jednej podstrony na drugą, korzystając ze znajdujących się tam linków. Zdaniem specjalistów SEO jakiś czas temu przeglądanie i indeksowanie strony internetowej odbywało się na dwa sposoby: fresh crawl oraz deep crawl. Oba procesy służyły przeszukiwaniu sieci w celu dotarcia do jak największej liczby witryn znajdujących się w sieci oraz pobraniu jak najaktualniejszych informacji o stronie. Pokrótce:
- fresh crawl („przeszukiwanie na świeżo”) – Googlebot odwiedzał strony często aktualizowane, sprawdzał co uległo zmianie i wprowadzał nowe dane do indeksu. Działo się tak w przypadku witryn, które często poprawiały zawartość strony.
- deep crawl („przeszukiwanie głębokie”) – Googlebot odwiedzał strony przechodząc z linku na link i zbierał informacje dotyczące zawartości witryny – zarówno pod kątem już istniejących, jak i nowo zaktualizowanych elementów.
Od tego czasu Google zmienił znacząco sposób działania robotów indeksujących, na co uwagę zwraca wielu specjalistów SEO. Jednak proces ten nie został jeszcze ani szerzej poznany, ani oficjalnie nazwany. Powyższe informacje na temat fresh crawlu i deep crawlu należy traktować raczej jako ciekawostkę dotyczącą możliwego działania Googlebotów niż aktualną informację. Pewne jest jednak, że indeksowanie odbywa się na tyle często, aby stale aktualizować wyniki SERP.
W jaki sposób bot trafia na twoją witrynę? W sporym uproszczeniu drogę tę można zaprezentować następująco:
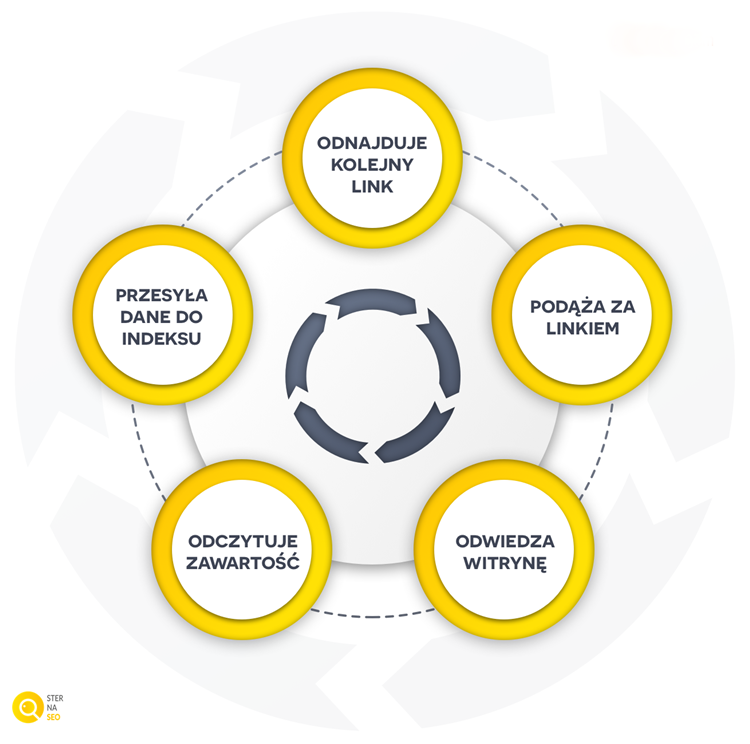
W rzeczywistości jednak Googlebot może wejść na stronę także za sprawą mapy witryny, która została zgłoszona w Google Search Console lub po prostu wrócić do strony, którą indeksował jakiś czas temu. Cykl ten pokazuje jednak, w jaki sposób wygląda prowadzony przez robota proces indeksowania strony internetowej.
Rola robotów w pozycjonowaniu stron internetowych
Googleboty mają istotny wpływ na pozycjonowanie strony internetowej. Najprościej ujmując: jeśli strona internetowa nie zostanie zaindeksowana przez robota, nie będzie widoczna w wynikach wyszukiwania Google.
Regularne przechodzenie z jednej strony na drugą wpływa na wiele aspektów istotnych dla widoczności witryny w wynikach wyszukiwania. Ważne jest, aby regularnie aktualizować informacje znajdujące się na stronie, w kodzie i na mapie strony oraz optymalizować witrynę zgodnie z wytycznymi webmasterów Google oraz potrzebami użytkowników sieci.
Za każdym razem, gdy dokonujesz zmian w witrynie, powinieneś mieć na uwadze obecność Googlebotów. W ramach optymalizacji konieczne jest zaprojektowanie strony internetowej w sposób, który ułatwi im poruszanie się po witrynie, a także zmusi do omijania tych podstron, których zawartość może niekorzystnie wpływać na pozycjonowanie.
Indeksowanie a roboty Google
Rodzaje robotów indeksujących Google
Istnieje kilka rodzajów Googlebotów, a każdy z nich odpowiedzialny jest za indeksowanie stron internetowych o różnym charakterze. Inny pełzacz zajmie się witryną dostosowaną do działania komputerów stacjonarnych, a inny będzie sprawdzał jej mobilną wersję – w tym dla różnych typów urządzeń mobilnych.
W sieci poruszają się Googleboty rejestrujące treści wideo (Googlebot Video), zdjęcia (Googlebot Images), a także newsy (Googlebot News). AdsBot i jego odmiany przyglądają się reklamom widocznym na stronie internetowej, a jeszcze inne analizują aplikacje internetowe, np. dla systemu Android. Wszystkie mają jednak ten sam cel: przeszukać witrynę, a na podstawie zdobytych informacji zaindeksować ją i udostępnić użytkownikom sieci.
Dostęp robotów indeksujących do wybranych podstron można zablokować za sprawą pliku robots.txt. Po wprowadzeniu określonej komendy wybrana podstrona lub jej element nie będzie dla nich dostępny. Dla przykładu, Googlebot News nie zaindeksuje treści ze strony dla narzędzia Wiadomości Google, a Googlebot Images nie zaindeksuje grafik – o tym jak to zrobić, dowiesz się w dalszej części artykułu
Najważniejsze elementy sprawdzane przez boty internetowe
Najważniejszym elementem dla wyszukiwarki Google jest strona główna witryny. Chcąc ułatwić robotom skanowanie jej zawartości, należy zadbać o właściwą nawigację na stronie głównej.
Pierwszym elementem, na którym skupia się uwaga Google botów, jest plik robots.txt, który powinien znajdować się w głównym katalogu serwera. To on określa, które pliki i treści mają zostać pominięte przy tworzeniu indeksu dla wyszukiwarki.
Pobieranie informacji ze strony internetowej możliwe jest także dzięki mapom witryn dostarczanym przez właścicieli stron. Zawarte w niej adresy URL są brane pod uwagę przez Googleboty podczas przeszukiwania strony. Plik tego typu nie gwarantuje jednak, że wszystkie zawarte w mapie witryny podstrony zostaną ujęte w indeksie.
W dalszej kolejności roboty przechodzą do pobierania danych z treści zawartych na stronie internetowej, w tym meta tagów, linków oraz znaczników. Następnie robot indeksujący zbiera informacje dotyczące pozostałych treści, w tym opisów grafik oraz opublikowanych tekstów. W międzyczasie znajduje link, za którym podąża w poszukiwaniu kolejnych stron internetowych wymagających zaindeksowania.
Wyróżnia się kilka map witryny , do najważniejszych należy jednak plik XML dedykowany robotom indeksującym. Zaleca się, aby mapa witryny została zgłoszona do Google Search Console. Dzięki temu zostanie szybciej zauważona przez roboty Google, a jednocześnie mamy możliwość weryfikowania stopnia indeksacji witryny.
Ze względu na to, że Googleboty pobierają całe mnóstwo danych ze strony, istotne jest stosowanie się do wytycznych wyszukiwarki internetowej. W tytule, meta description, alternatywnych opisach obrazków oraz tekstach powinny znaleźć się frazy i ich konotacje (wyrażenia powiązane). Istotne jest również, aby zadbać o jakość tych elementów, jak: prosta konstrukcja adresu URL, obecność linków zewnętrznych, stosowanie nagłówków, unikatowe treści, mapa witryny czy prawidłowo nazwane kategorie.
Nie inaczej jest w przypadku pozostałych elementów, jak filmy czy zdjęcia – one również, za sprawą określonych rodzajów Googlebotów, są brane pod uwagę przy zbieraniu danych do indeksu. Budowa strony internetowej musi być przemyślana w każdym calu, zgadzać się z wytycznymi dotyczącymi zawartości witryny, a także być stale aktualizowana i dopasowywana do algorytmów wyszukiwarki Google.
Strona internetowa może zostać zaindeksowana, ale nie oznacza to, że od razu znajdzie się w Top10. Musi spełniać cały szereg wymogów, aby z czasem zyskiwać coraz większe uznanie w oczach algorytmów Google.
Których podstron nie należy indeksować i dlaczego?
Do podstron, których nie należy indeksować należą te, które z pewnych przyczyn zostają powielone w obrębie jednej domeny, zawierają wrażliwe bądź poufne dane lub powstały wyłącznie na potrzeby użytkowników. Będą to również wszystkie miejsca pozbawione treści (puste strony) lub których zawartość po zaindeksowaniu może obniżyć jakość strony ocenianą następnie przez algorytmy (niepełna oferta, strony testowe).
Ten rodzaj podstron występuje najczęściej w sklepach internetowych oraz na blogach i są to między innymi:
- koszyki zakupowe i podstrony z zamówieniami produktów/usług
- kategorie produktów, z których – ze względu na specyfikę branży – niemożliwe jest usunięcie duplikatów treści
- formularze logowania, rejestracji oraz zapisu do newslettera
- strony konwersji – przekierowania po dokonaniu zakupów, zapisu do newslettera czy podziękowanie za wypełnienie ankiety
- regulaminy i dokumenty związane z polityką prywatności lub/i przepisami prawa
- wewnętrzna wyszukiwarka i filtrowane przez nią wyniki
- pliki cookies i certyfikaty strony
Jak widać, są to te struktury, które nie odgrywają ważniejszej roli z perspektywy indeksowania – do nich dostęp ma jedynie użytkownik sieci, który zechce skorzystać z konkretnych, proponowanych w jej obrębie usług.
Aby nie zaszkodzić pozycjonowaniu, warto rozważyć zablokowanie robotom dostępu do wybranych treści – jak te wskazane powyżej. Pomocne okażą się w tym następujące działania, które poinformują Googlebota, że dana strona nie ma podlegać indeksowaniu:
Plik robots.txt zablokuje botom dostęp do określonych miejsc na stronie po wprowadzeniu komendy:
User-agent:
Disallow:
Np.
User-agent: Googlebot
Disallow: /strona.html
Atrybut nofollow oraz noindex między znacznikami <head></head> w dokumencie HTML wskaże botom, że tę podstronę należy pominąć podczas indeksowania:
<meta name=”robots” content=”noindex, nofollow”>
Narzędzie Google Search Console, dzięki któremu można na jakiś czas usunąć wybrane adresy URL z wyników wyszukiwania Google.
Kiedy Googlebot nie widzi strony internetowej?
Istnieją sytuacje, w których Googlebot nie widzi strony internetowej. Przyczyn istnieje co najmniej kilka:
- witryna wciąż jest stosunkowo nowa i nie została jeszcze zauważona przez roboty Google,
- do strony nie odsyłają żadne linki zewnętrzne,
- w witrynie w ostatnim czasie uległy zmianie adresy URL (np. strona została przeniesiona na protokół HTTPS) bez wdrożenia odpowiedniego przekierowania.
Nieco odmienna sytuacja ma miejsce, gdy Google bot teoretycznie widzi stronę, ale wskutek innych problemów witryna nie wyświetla się w wynikach wyszukiwania. Tu należy upatrywać takich przyczyn, jak np.:
- plik robots.txt został niewłaściwie przygotowany i zablokował przed indeksacją elementy istotne dla pozycjonowania strony internetowej,
- dostęp jest niemożliwy przez zastosowanie tagu „noindex”,
- dostęp jest niemożliwy przez zastosowanie procesu uwierzytelniania lub logowania (np. ochrona hasłem),
- brak dostępu spowodowany jest błędem serwera – a zatem sytuacją, w której serwer jest przeciążony lub wyłączony, a także jeśli upłynął limit czasu oczekiwania na odpowiedź serwera,
- blokowanie IP robota (blokowanie botów internetowych z poziomu sieci danego serwera),
- strona została usunięta z indeksu z powodu naruszenia wytycznych Google dla webmasterów.
Aby przekonać się, czy witryna została zaindeksowana, użyj komendy site: i sprawdź, czy strona wyświetla się w wynikach (przykładowo site:example.pl). Innym sposobem jest zastosowanie komendy info: w okienku wyszukiwarki (przykładowo info:example.com). Jeśli w wynikach wyświetla się twoja witryna oznacza to, że została zaindeksowana.
Podsumowanie













