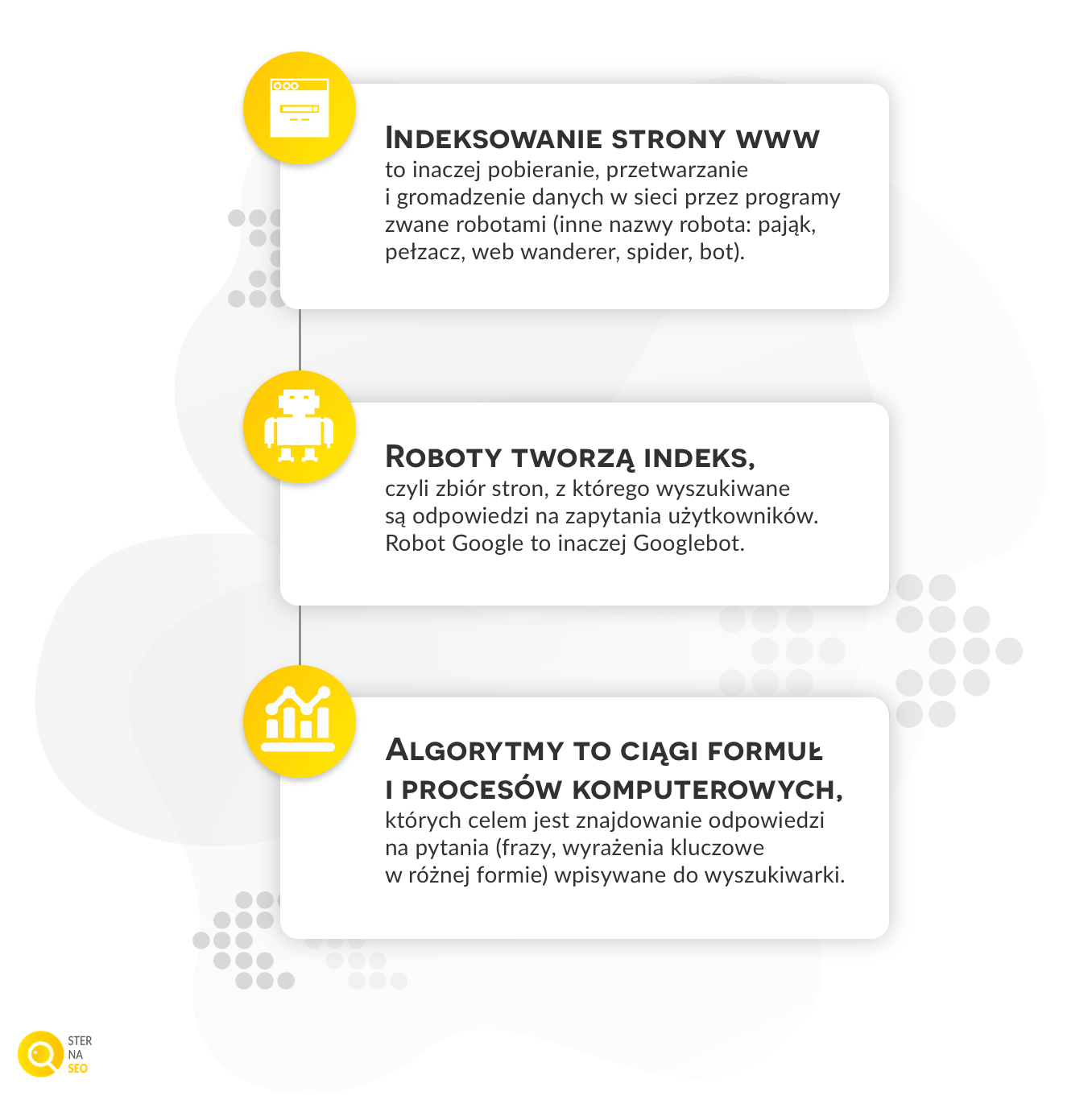
Indeksowanie to zbieranie informacji o treści, frazach kluczowych, linkach i obrazach znajdujących się na stronie i zapisywanie ich w bazie danych wyszukiwarki. Korzystając z wyszukiwania, przeszukujemy właśnie tę bazę danych (indeks), a nie wszystkie witryny w internecie bezpośrednio. Za indeksowanie strony odpowiadają specjalne programy, czyli roboty sieciowe (inne nazwy robota: robot internetowy, pająk, pełzacz, web wanderer, spider, bot). Na naszym blogu o pozycjonowaniu stron znajdziecie specjalnie przygotowany słownik SEO z wyjaśnieniem tych i innych pojęć.
Jedno zapytanie – tysiące adresów potencjalnie zawierających odpowiedź. W dużym uproszczeniu można przyjąć, że Google zna odpowiedź na zapytanie, jeszcze zanim wpiszemy je do wyszukiwarki. Wszystko dlatego, że na bieżąco tworzy indeks wyszukiwania i porządkuje w nim informacje. Aby lepiej zrozumieć ten proces należy cofnąć się do początku istnienia witryny. Nowo założona lub zaktualizowana witryna www, która trafia do internetu, zostaje przeskanowana przez Google, a konkretnie przez specjalny program skanujący. Po zdobyciu informacji na temat danej witryny, Google wprowadza ją do indeksu, czyli do bazy danych. A zatem, szukając informacji w internecie, przeszukujemy tak naprawdę indeks Google.
W indeksowaniu stron udział biorą programy nazywane robotami indeksującymi. Podążając za linkami zawartymi na podstronach, roboty indeksują strony www jedna za drugą. Po wpisaniu zapytania oprogramowanie przeszukuje indeks i znajduje wszystkie strony, odpowiadające zapytaniu wpisanemu przez użytkownika w okno wyszukiwarki. W ten sposób uzyskujemy naprawdę olbrzymie ilości wyników. Aby umożliwić użytkownikowi uzyskanie jak najdokładniejszej odpowiedzi na zadane zapytanie, Google wykorzystuje algorytmy, które na podstawie kilkuset różnych czynników selekcjonują strony www w indeksie. Procesy działania algorytmów są niezwykle złożone. Dość powiedzieć, że pod uwagę brane są m.in. liczba i rozmieszczenie słów kluczowych, występowanie odpowiednich kolokacji, czyli wyrażeń powiązanych, jakość witryny i wiele, wiele innych. Cały proces ustalenia pozycji witryny i wyświetlenia wyników wyszukiwania zajmuje wyszukiwarce Google zaledwie ok. pół sekundy.
Ile adresów www mieści się w indeksie? Setki miliardów. Zajmują one ponad 100 000 000 gigabajtów. Google przypisuje stronę internetową do indeksu zgodnie ze słowami, jakie ona zawiera.
Pobieranie i indeksowanie a działanie algorytmów
Aby możliwe było wskazanie witryny najlepiej odpowiadającej na zapytanie użytkownika, muszą zadziałać algorytmy. To dzięki nim wyniki w indeksie są selekcjonowane i porządkowane w określonej kolejności. Google nieustannie pracuje nad udoskonalaniem swoich algorytmów, dzięki czemu potrafią już one nie tylko rozpoznać same słowa kluczowe, lecz także kontekst ich wykorzystania, a nawet literówki, które mogą pojawiać się przy wpisywaniu zapytania. Algorytmy oceniają jednak nie tylko tekst, lecz także inne aspekty, takie jak zaufanie do witryny, wiarygodność i merytoryczność treści, jakość linków, a nawet… intencje użytkownika!
Indeksowanie strony w Google a crawling
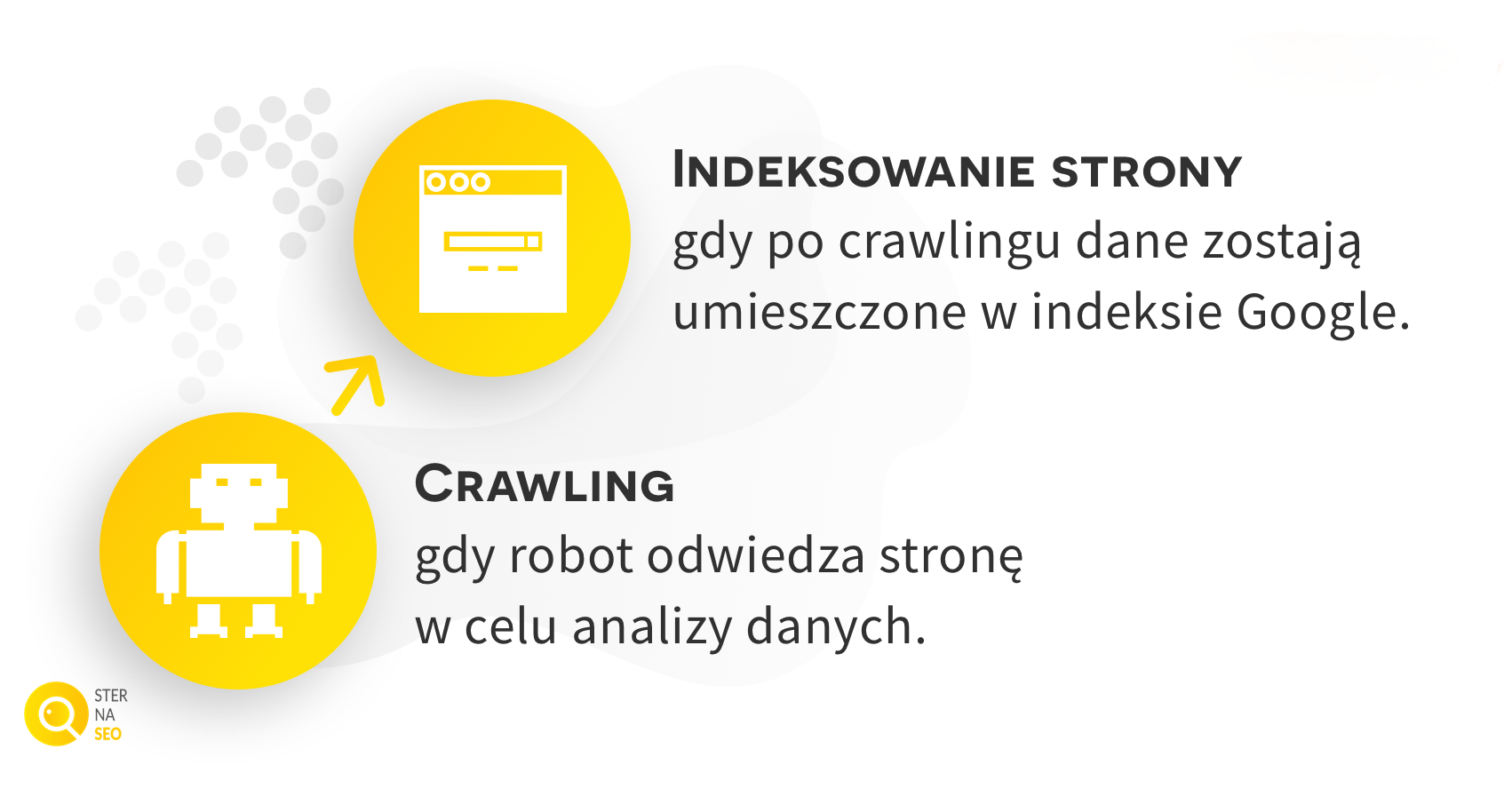
Wiemy już co to jest indeksowanie strony w Google. Jednak w kontekście funkcjonowania wyszukiwarki można też spotkać pojęcie crawling (można to tłumaczyć jako: pełzanie, czołganie, łażenie – tak jak przemieszczają się robaki lub pająki; patrz: inne nazwy robota). Crawling to jeszcze nie indeksowanie strony, a jedynie przechodzenie robota pomiędzy podstronami.
Crawling (można spotkać się też ze słowem: crawlowanie) to po prostu wysłanie bota na witrynę, celem jej przeanalizowania, natomiast indeksowanie to pobieranie, przetwarzanie i gromadzenie danych celem włączenia strony www do indeksu wyszukiwarki. Przeprowadzenie crawlingu nie oznacza, że adres został zaindeksowany i że pojawi się w wynikach wyszukiwania.
Umieszczenie adresu www w indeksie jest następnym etapem po crawlingu. Nie każda strona po crawlingu jest zaindeksowana, lecz każda zaindeksowana została wcześniej poddana crawlingowi.
Co to jest indeksowanie mobile-first?
Indeksowanie mobile-first to sposób indeksowania, w którym roboty biorą pod uwagę w pierwszej kolejności mobilną wersję strony. Gdy mówimy o indeksowaniu mobilnym, to wciąż mówimy o nim w kontekście jednego indeksu Google. Indeks jest jeden i nie ma osobnego dla urządzeń mobilnych. Rodzaj urządzenia (mobilne czy desktopowe) nie ma znaczenia na etapie indeksowania.
Mobile-first a pozycje witryny
Indeksowanie mobile-first dotyczy zasadniczo tylko tych serwisów internetowych, które posiadają wersję dostosowaną do urządzeń mobilnych. Tej metodzie nie podlegają witryny, które wersji mobilnej w ogóle nie posiadają. Na podstawie wersji mobilnej Google ustala ranking także dla wyników desktopowych. Google sam stwierdza, kiedy strona www jest gotowa na mobile-first. Serwisy nieposiadające wersji mobilnej nie wypadną z indeksu, jednak mogą wyświetlać się na niższych pozycjach w wynikach wyszukiwania. Wszystko dlatego, że wcześniej pozycja witryny zależała od oceny wersji desktopowej, a teraz w pierwszej kolejności pod uwagę brana jest wersja mobilna. Jeśli jakaś witryna nie posiada wersji mobilnej, roboty indeksujące wezmą pod uwagę wersję desktopową.
W praktyce indeksowanie mobile-first oznacza, że przy określaniu pozycji w wynikach wyszukiwania brana będzie pod uwagę wersja mobilna strony internetowej. Oczywiście wprowadzenie tej metody przez wyszukiwarkę Google podyktowane jest rosnącym znaczeniem urządzeń mobilnych w codziennym życiu.
Czy wiesz, że…
Google to wyszukiwarka globalna i posiada jeden indeks. Jednak w obrębie jednego indeksu posiada osobne indeksy dla każdego kraju. Dzięki indeksom krajowym możliwe jest dostosowanie wyników do zwyczajów związanych z wyszukiwaniami w danym kraju, nie licząc oczywiście wersji językowej. Wszystko po to, aby zaspokoić oczekiwania użytkowników wyszukiwarki w danym kraju. Indeksy lokalne są szczególnie istotne z punktu widzenia wyszukiwań usług i miejsc specyficznych dla lokalizacji użytkownika.
Budżet indeksowania
Budżet indeksowania witryny (Crawl Budget) to określenie na maksymalną liczbę danych, które wyszukiwarka Google może pobrać z danej domeny w trakcie jednej wizyty Googlebota. Aby jak najlepiej zrozumieć, co to jest budżet indeksowania strony, należy wziąć pod uwagę dwa obszary:
a) crawl rate limit – limit częstotliwości crawlowania,
b) crawl demand – zapotrzebowanie na indeksowanie.
W przypadku częstotliwości crawlowania (crawl rate limit) chodzi o to, że podczas jednej wizyty na witrynie internetowej roboty chcą zaindeksować jak największą liczbę adresów URL, jednak bez nadmiernego obciążenia serwera, aby nie wpływać negatywnie na doświadczenia użytkowników. Częstotliwość crawlowania można ograniczyć za pomocą Google Search Console, np. w sytuacji, gdy crawlowanie przeciąża serwer. Ustawiona w GSC częstotliwość będzie maksymalną, jaką Googlebot będzie w stanie osiągnąć. Częstotliwość crawlowania dla danej witryny jest ustanawiana algorytmicznie tak, aby była optymalna. Google odradza ograniczanie częstotliwości crawlowania, chyba że administrator witryny ma pewność, że to właśnie Googlebot jest przyczyną przeciążenia serwera.
Zapotrzebowanie (crawl demand) oznacza z kolei działanie mające na celu „zachęcenie” botów do częstszego odwiedzania witryny. Częściej odwiedzane są witryny popularne oraz często aktualizowane (zmiany na stronie www wymuszają częstsze wizyty crawlerów).
Crawl Budget – budżet indeksowania witryny – to, mówiąc w dużym uproszczeniu, liczba adresów URL, które wyszukiwarka może i chce zaindeksować. Na budżet indeksowania składają się takie czynniki, jak częstotliwość crawlowania oraz zapotrzebowanie (crawl demand). Jest wyrażony w MB.
Domeny internetowe posiadają budżet dzienny wyrażany w megabajtach. Boty pełzają po podstronach aż do limitu i przerywają indeksowanie po wykorzystaniu budżetu. Następnie wracają, aby sprawdzić, czy w międzyczasie na pobranych już adresach nie nastąpiły aktualizacje. W takim układzie może się okazać, że podstrony zlokalizowane bardzo głęboko w architekturze witryny mogą w ogóle nie zostać zaindeksowane. Dlatego korzystniej jest mieć witrynę o prostszej konstrukcji, z ważnymi podstronami umieszczonymi wysoko w hierarchii. Kiedy robot wraca na witrynę? Tego niestety nie wiemy. W praktyce bot codziennie pełza po witrynie internetowej, ale nigdzie nie jest zdefiniowane, kiedy przerywa crawlowanie i kiedy ewentualnie wróci.
Kiedy moja strona www jest indeksowana?
Publikując nową stronę internetową warto wiedzieć czy została ona już zaindeksowana, czyli czy będzie już pojawiać się w wynikach wyszukiwania. Jak sprawdzić czy strona została zaindeksowana? Na przykład poprzez wpisanie w okno wyszukiwarki polecenia „site:” i po dwukropku adres witryny. Jeżeli wyszukiwanie zwróci wyniki, witryna została zaindeksowana. Jeśli nie będzie żadnych wyników, witryna nie została pobrana przez Googlebota (polecenie „site:” można stosować pomocniczo, jednak należy mieć świadomość, że nie jest to najdokładniejsze narzędzie do sprawdzania stanu indeksacji).
Innym sposobem jest oczywiście sprawdzenie raportu ze statystyk indeksowania w Google Search Console. To podstawowe narzędzie do badania kondycji i stanu indeksacji, które zawiera informacje na temat działań, jakie Googlebot wykonał na witrynie w ciągu ostatnich 90 dni. Czy są sposoby na to, aby stymulować indeksowanie strony w wyszukiwarkach oraz czy można rozpoznać kiedy witryna była indeksowana w wyszukiwarce?
Jak długo trwa indeksowanie strony?
Nie można udzielić jednoznacznej odpowiedzi na to pytanie. Nawet sama firma Google nie podaje przybliżonego czasu indeksowania stron. Odnalezienie i pobranie nowej witryny może zająć kilka dni, ale równie dobrze kilka miesięcy.
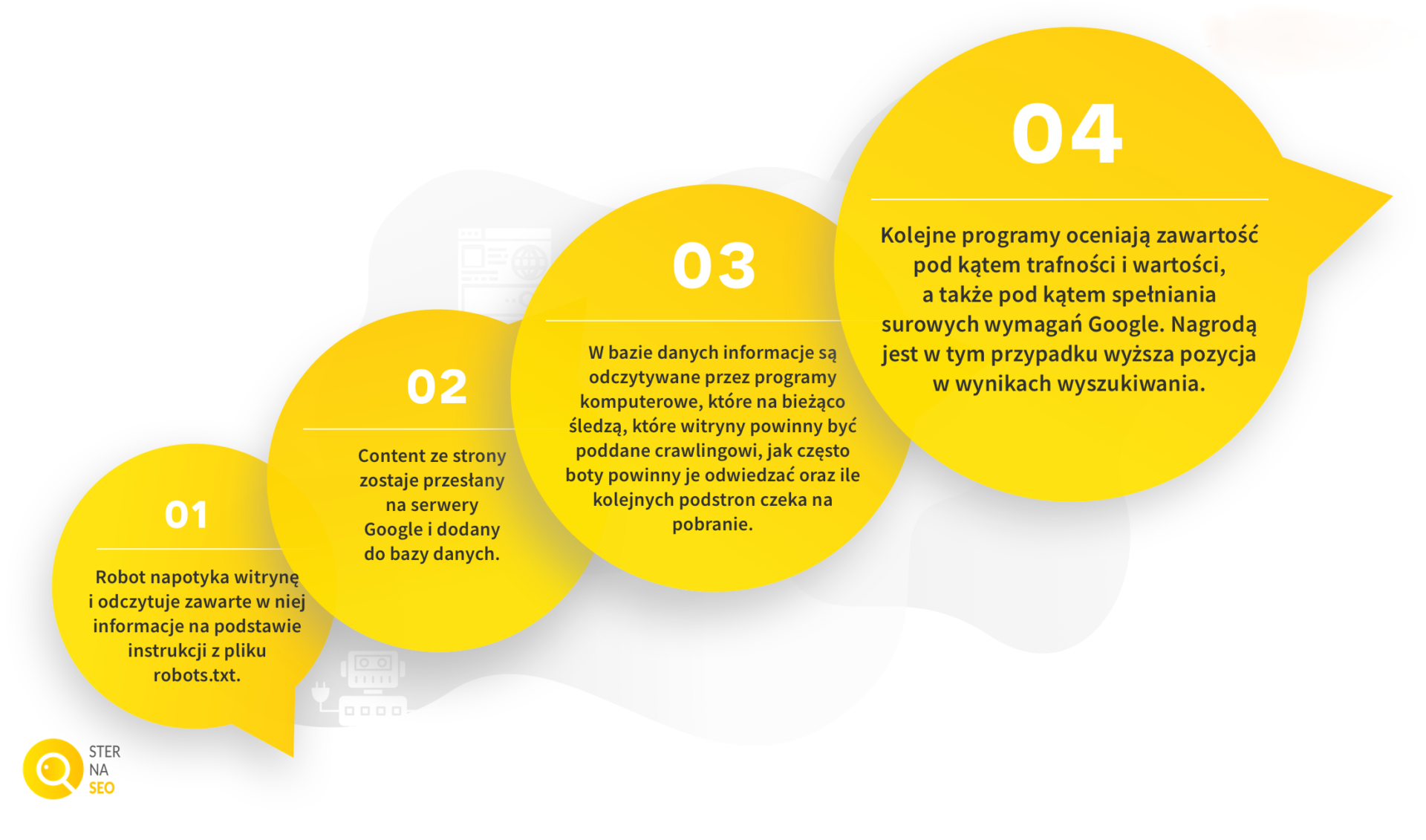
Za indeksowanie strony w Google odpowiadają algorytmy oraz Googlebot. Roboty sieciowe, czyli de facto programy komputerowe, podlegają pewnym ograniczeniom wynikającym choćby z prędkości przesyłania danych czy pojemności serwerów.
Cykliczność indeksowania
Indeksowanie strony www ma charakter cykliczny, dlatego warto nieustannie dbać o wysoką jakość witryny oraz wprowadzanych aktualizacji, aby osiągać wyższe pozycje bądź nie spadać w wynikach wyszukiwania. Po pierwszych odwiedzinach witryny roboty wracają co jakiś czas, aby sprawdzić i zaindeksować ewentualne zmiany. Im częściej roboty napotykają nowy, wartościowy content, tym większe prawdopodobieństwo, że będą częściej na witrynę wracać. A im szybciej nasze nowe treści zostaną zaindeksowane, tym szybciej zaczną się wyświetlać w wynikach wyszukiwania.
Jak skłonić Google do indeksowania nowej strony?
Czy szybkie indeksowanie strony w wyszukiwarkach jest możliwe? Jest kilka sposobów, które mogą skłonić roboty do częstszego odwiedzania witryny i jej szybszego zaindeksowania (co jest szczególnie ważne w przypadku nowych witryn).
Zanim jednak uruchomiona zostanie całkowicie nowa witryna, należy sprawdzić czy plik robots.txt pozwala Googlebotowi prawidłowo indeksować stronę www.
Jak skonfigurować plik robots.txt dla Googlebota?
Plik robots.txt służy do komunikacji z robotami sieciowymi. Zawiera on komendy kierujące ruchem robotów, a dokładniej zalecające im, w jakim kierunku mogą się udać „pełzając” po witrynie. Za pomocą tych komend można wskazać, które adresy URL roboty mogą odwiedzić, a do których nie mają mieć dostępu. Plik robots.txt jest pierwszym miejscem, jakiego poszukują boty trafiające na witrynę internetową.
Z punktu widzenia pozycjonowania warto podkreślić, że komendy zawarte w pliku robots.txt mają charakter zaleceń, a nie bezwzględnego blokowania dostępu. Google zapewnia, że Googlebot stosuje się do zaleceń w robots.txt, jednak pamiętać należy, że nie jest to jedyny robot sieciowy odwiedzający witryny internetowe. Dla innych botów komendy te mogą nie mieć znaczenia.
Prawidłowe skonfigurowanie pliku robots.txt jest podstawową rzeczą, jaką należy wykonać, jeśli chcemy, aby nowa strona została zaindeksowana przez wyszukiwarkę. Przede wszystkim należy upewnić się, że nie blokujemy Googlebotowi możliwości indeksacji ważnych stron.
Jakich podstron nie udostępniać robotom sieciowym? Na przykład takich, które prezentują nieunikalne treści oraz tych w wersjach testowych, nad którymi prace jeszcze trwają.
Na szybkie indeksowanie strony internetowej w wyszukiwarkach wpłynąć mogą także następujące czynniki:
- Konfiguracja Search Console – narzędzi, dzięki którym użytkownik może obserwować m.in. ruch na witrynie. Dzięki Search Console administrator ma możliwość np. zgłosić do Google prośbę o ponowne zaindeksowanie adresów URL bądź ograniczyć częstotliwość indeksowania.
- Linki zewnętrzne – linki do stron zamieszczonych w witrynie, w tym nawigacji, a także linki do witryny zamieszczane w wartościowych i często indeksowanych witrynach, w tym na forach bądź w serwisach społecznościowych.
- Przesłanie mapy witryny do Search Console – działa jak komunikat dla robota: „Oto gotowa lista podstron, możesz indeksować”.
Z punktu widzenia istniejącej, aktywnej już strony www ważne jest stworzenie strategii budowania treści – witryna musi być regularnie aktualizowana i uzupełniana o nowe, jakościowe treści. Częste aktualizacje zachęcają roboty sieciowe do częstszych odwiedzin.
Co jest ważne dla indeksowania stron www?
Nim nie indeksowanie strony w Google nie zostanie przeprowadzone, nie pojawi się ona w wynikach wyszukiwania. Dlatego trzeba podejmować działania opisane powyżej, które sprowokują Googlebota do odwiedzenia witryny. Googlebot skanuje witryny algorytmicznie, z określoną częstotliwością, poczynając od stron wygenerowanych w poprzednich procesach crawlingu i biorąc pod uwagę mapy witryn stworzone przez webmasterów. W ten sposób robot wykrywa nowe strony internetowe oraz wszelkie aktualizacje i zmiany.
Ważne również jest sporządzenie mapy strony. Co to jest? Jest to dokument XML zawarty na serwerze witryny internetowej i zawierający listę wszystkich podstron tworzących witrynę. Dzięki mapie robot Google widzi, kiedy dodajesz nowe podstrony, a im częściej dany serwis jest aktualizowany, tym częściej odwiedzają go roboty wyszukiwarki. Mapę należy dodać do Google Search Console (niezbędne jest do tego posiadanie konta Google oraz, oczywiście, zweryfikowanie samej strony w Google Search Console).
Dlaczego dodanie mapy może przyspieszyć indeksowanie strony w wyszukiwarkach? W normalnych warunkach po opublikowaniu nowej witryny, bot musi do niej dotrzeć, a następnie ją scrawlować (przy czym w przypadku witryn o rozbudowanej architekturze na pewno nie zaindeksuje całości od razu). Obrazowo mówiąc, dodając mapę do GSC, dajemy Googlebotowi gotową listę podstron i skłaniamy go do indeksowania. Bez mapy strona też zostałaby pobrana, tylko wolniej.
Jak sprawdzać stan indeksowania strony?
W Google Search Console (darmowej platformie stworzonej przez Google dla administratorów witryn internetowych) użytkownik (administrator) ma dostęp m.in. do raportu ze statystyk, który zawiera informacje na temat działań, jakie Googlebot wykonał na witrynie w ciągu ostatnich 90 dni. Linia na wykresie powinna wzrastać odpowiednio do rozwoju witryny. Wykres wskazuje na stan indeksowania, a więc m.in. liczbę stron www w indeksie oraz problemy z indeksowaniem.
Ze spadkiem możemy mieć do czynienia m.in. w przypadku dodania nowej reguły do pliku robots.txt albo błędów w kodzie HTML, które uniemożliwiają robotom odczytanie treści. Inną przyczyną spadku na wykresie może być spowolnienie działania witryny (wówczas roboty przesyłają mniej danych, aby nie przeciążać serwera). Podobnie rzecz wygląda w przypadku błędów połączenia z serwerem. Słaba jakość treści bądź rzadkie jej aktualizacje również mogą przyczynić się do spowolnionego indeksowania strony. Wówczas warto zastanowić się nad ogólnym ulepszeniem strony internetowej, co z pewnością przyniesie korzyści także w jej pozycjonowaniu.
Wzrost częstotliwości indeksowania strony zauważalny na wykresie może nastąpić w przypadku dodania dużej ilości treści o wysokiej jakości, w tym przydatnych dla użytkowników. W przypadku przeciążenia serwera witryny bądź uznania, że Googlebot zbyt często indeksuje stronę, można zastosować następujące metody:
- ustawienie kodu HTTP 503 (Service Unavailable – usługa niedostępna – serwer nie jest w stanie w danej chwili zrealizować zapytania ze względu na przeciążenie) jako odpowiedzi na prośby Googlebota,
- doprecyzować instrukcje w pliku robots.txt i zablokowanie dostępu do adresów URL, których odczytywania nie chcemy.
Podsumowanie

Mamy nadzieję, że kolejna część naszego poradnika SEO wyjaśniła Wam nieco więcej na temat tego, jak działa indeksowanie strony w Google i przybliżyła do zrozumienia tajników pozycjonowania. Będziemy wdzięczni za wszelkie komentarze, pytania i sugestie dotyczące zarówno tej, jak i pozostałych części serii Audyt SEO, regularnie publikowanych na naszym blogu!
Podsumowanie wiadomości na infografice

Źródła: Google – Pomoc 1, 2, 3; Google.com 1, 2, 3; LinkedIn; Shout Me Loud; Search Metrics; Impact BND; Neil Patel; BM Magazine; MOZ; Search Engine Journal












