 7:25 min
7:25 min
 Anna Grubich
04.03.2020
Anna Grubich
04.03.2020
Czym jest TF*IDF i jak wpływa na pozycjonowanie
Jedną z metod, która pomaga dostosować niezbędne frazy do danego contentu jest TF*IDF. Korzystając z niej można dowiedzieć się, czy nasycenie jest odpowiednie, a także znaleźć wyrażenia powiązane, które pozwolą zwiększyć tematyczność tekstu oraz wykorzystać możliwość wyświetlania się na bardziej niszowe zapytania.
W minionych latach Google wykorzystywało wiele rozwiązań, mających na celu usprawnienie wyszukiwania semantycznego, o czym regularnie piszemy na naszym SEO Blogu.
TF*IDF jest to iloczyn dwóch czynników – Term Frequency (częstotliwość wyrażenia) oraz Inverse Document Frequency (odwrotna częstotliwość w dokumentach). Dzięki tego typu statystyce numerycznej uzyskujemy wagę danej frazy bądź wyrażenia w korpusie językowym, czyli zbiorze badanych dokumentów.
TF*IDF jest mocno powiązane z techniką LSI (latent semantic indexing) – utajonego indeksowania semantycznego, stosowanego przez wyszukiwarkę Google. Jest to sposób indeksowania treści w zbiorze dokumentów pod kątem ich znaczenia i tematyczności.
W uproszczeniu wygląda to tak, że tekst jest sprawdzany pod kątem rzeczywistego znaczenia poszczególnych słów/wyrażeń. W rezultacie tworzy się tzw. „wektory znaczeniowe”, które pozwalają określić zakres tematyczny danego tekstu.
Takie spojrzenie pozwala ustalić dokładne znaczenie wyrażenia kluczowego i wyeliminować pomyłki dotyczące chociażby homonimów (identycznie wyglądających wyrazów o innych znaczeniach).
Frazy rozpoznawane dzięki LSI jako „tematyczne” są wyrazami, które pozwalają algorytmom Google zrozumieć tematykę danego tekstu.
Jako przykład weźmy słowo „zamek”. W języku polskim posiada ono trzy różne znaczenia – budowla, mechanizm zamykający drzwi, a także zapięcie garderoby. Słowa użyte w tekstach o różnych „zamkach” będą różnić się, w zależności od znaczenia wyrazu „zamek” mimo tego, że brzmi i wygląda on tak samo. Możemy wymienić chociażby takie wyrażenia:
- zamek (budowla) – wieże, baszty, warownia, wały, rycerze, itp.
- zamek (mechanizm zamykający drzwi) – drzwi, brama, klucz, rygiel, itp.
- zamek (część garderoby) – spodnie, rozporek, kurtka, tkanina, itp.
Dzięki tej technice można odróżnić w korpusie dokumenty dotyczące wyrażeń o różnych znaczeniach. Warto wspomnieć, że wyżej opisana technika zastąpiła logikę Boole’a, która opierała się na metodzie 0-1. Pozwalała bowiem znaleźć dane wyrażenia w dokumencie, jednak nie odróżniała znaczenia danych wyrazów.
Po ustaleniu fraz czy wyrażeń powiązanych dzięki LSI, wylicza się ich wagę w dokumencie bądź korpusie. W tym celu stosuje się wzór TF*IDF.
Warto na wstępie przedstawić kilka ważnych pojęć, które będą wykorzystywane w wyjaśnianiu metody TF*IDF.
Dokument – tekst, który zamierzamy zbadać pod kątem nasycenia czy tematyczności.
Fraza – główne wyrażenie kluczowe, którego nasycenie chcemy zbadać.
Korpus – jest to zbiór dokumentów, do którego chcemy porównać badany dokument; w zależności od potrzeb może to być TOP10 wyszukiwarki czy kilka tematycznych artykułów.
Waga wyrażenia/frazy – liczba występowania danej frazy w odniesieniu do liczby słów całego dokumentu. Nie uwzględnia ona tzw. stop słów.
Wyrażenia powiązane – są to frazy, które zwiększają/określają tematyczność całego tekstu.
SERP – organiczne wyniki wyszukiwania.
Częstotliwość wyrażenia (TF)
TF (Term Frequency) pozwala określić
częstotliwość występowania danej frazy w konkretnym dokumencie. Jego zakres obejmuje wyłącznie jeden dokument, który ma być badany. Wartość ta jest wprost proporcjonalna do częstotliwości występowania wyrazu.
Aby obliczyć TF, należy podzielić liczbę wystąpień frazy w dokumencie przez liczbę znajdujących się w nim wszystkich słów. Przedstawia to poniższy wzór:
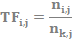
gdzie:
TFi,j – oznacza częstotliwość słowa i w dokumencie j,
ni,j – oznacza liczbę wystąpień słowa i w dokumencie j,
nkj – oznacza liczbę wystąpi wszystkich słów w dokumencie j.
Aby ułatwić zrozumienie całego schematu, posłużymy się przykładem. Powiedzmy, że chcemy obliczyć częstotliwość frazy „zamek”, występującej 34 razy w dokumencie, który zawiera 100 słów. Korzystając z powyższego wzoru na TF możemy więc ustalić, że:
ni,j – 34,
nkj – 100,
a więc:
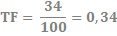
Na podstawie tych obliczeń możemy ustalić, że TF – częstotliwość występowania słowa „zamek” w badanym dokumencie wynosi 0,34.
Należy pamiętać, że podczas liczenia słów w dokumentach, Google nie bierze pod uwagę tzw. stop słów (stopwords). Są to wyrazy, które nie niosą ze sobą żadnych treści, przez co nie są liczone przez wyszukiwarkę. Należą do nich m.in. zaimki, liczebniki, przyimki i inne (np. a, aby, jakiż, jakkolwiek, jako, po, pod, podczas, pomimo, ponad, ponieważ, tylko, tym, u, w, wam, wami, was, wasz, wasza).
Odwrotna częstotliwość w dokumentach (IDF)
IDF (Inverse Document Frequency) pozwala sprawdzić, jak często dany termin występuje we wszystkich dokumentach badanego korpusu językowego. W zależności od potrzeb może być chociażby TOP10 wyników wyszukiwania, zbiór artykułów naukowych z danej dziedziny, konkretny zbiór tekstów, itp. Jest to odwrotna częstotliwość wyrażenia, dlatego też im częściej dany wyraz pojawia się w korpusie, tym wynik IDF będzie niższy.
Wartość tę można obliczyć z poniższego wzoru:
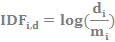
gdzie:
IDFi,D – odwrotna częstotliwość słowa i we wszystkich dokumentach korpusu D,
di – ogólna liczba dokumentów w badanym korpusie językowym,
mi – liczba dokumentów, które zawierają co najmniej jedno wystąpienie słowa i.
Wróćmy do naszego przykładu z „zamkiem”. Przyjmijmy, że w badanym korpusie, który zawiera 10 milionów dokumentów, wyrażenie „zamek” pojawia się w 300 000 dokumentach. Zatem dane do wzoru TF*IDF są więc następujące:
di – 10 000 000
mi – 300 000.
Powyższe dane pozwalają nam obliczyć odwrotną częstotliwość frazy i (IDFi,D):
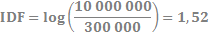
Gotowy wzór TF*IDF wygląda więc następująco:
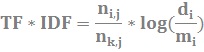
gdzie:
TF –częstotliwość słowa i w dokumencie j,
IDF – odwrotna częstotliwość słowa i we wszystkich dokumentach korpusu
ni,j –liczba wystąpień słowa i w dokumencie j,
nk,j –liczba wystąpień wszystkich słów w dokumencie j,
di – ogólna liczba dokumentów w badanym korpusie językowym,
mi – liczba dokumentów, które zawierają co najmniej jedno wystąpienie słowa i.
Otrzymany wzór TF*IDF pozwala wyliczyć iloczyn dla naszej przykładowej frazy „zamek”.
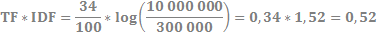
Czynniki TF oraz IDF można liczyć nie tylko w kontekście jednego wyrazu. Powszechne jest także stosowanie zestawów współwystępujących słów w danym korpusie. Nazywamy je N-gramami. Korzystając z tej teorii, wyróżniamy:
- ungramy – wyrażenie zawierające jeden wyraz,
- bigramy – wyrażenie zawierające dwa wyrazy,
- trygramy – wyrażenie zawierające trzy wyrazy,
- itd.
Sposób obliczania i wzór TF*IDF dla bigramów czy trygramów jest analogiczny do schematu z jednym wyrazem.
Należy pamiętać, że wyżej przedstawiony wzór TF*IDF jest jednym z najprostszych schematów. Aby dawał on miarodajne i rzetelne wyniki, jest w odpowiedni sposób normalizowany przez wyszukiwarkę. W zależności od preferencji można modyfikować poszczególne wzory. Czasami podczas liczenia IDF do wartości mianownika dodaje się 1, aby uniknąć ewentualnego dzielenia przez 0. Podczas liczenia TF natomiast wykorzystuje się dodatkowo wzór Pitagorasa. Poznaj potencjał swojej strony – zamów audyt SEO i skorzystaj z personalizowanych rekomendacji!
Co można wywnioskować z wartości TF*IDF?
Wartości te pozwalają zestawić częstotliwość występowania danej frazy w naszym dokumencie z korpusem językowym. To z kolei daje nam jasne wskazówki pod kątem SEO copywritingu – czy nasz tekst jest odpowiednio nasycony, a także tematyczny dla algorytmów Google (podczas badania obecności wyrażeń powiązanych przy pomocy LSI).
Dlatego też wyniki otrzymane ze wzoru TF*IDF zawsze będą względne – aby dać nam jakąkolwiek informację, powinny być zawsze zestawiane z wynikiem TF*IDF wszystkich dokumentów z naszej bazy. Korzystając z naszych przykładowych obliczeń frazy „zamek”, przedstawmy otrzymane dane na wykresie:
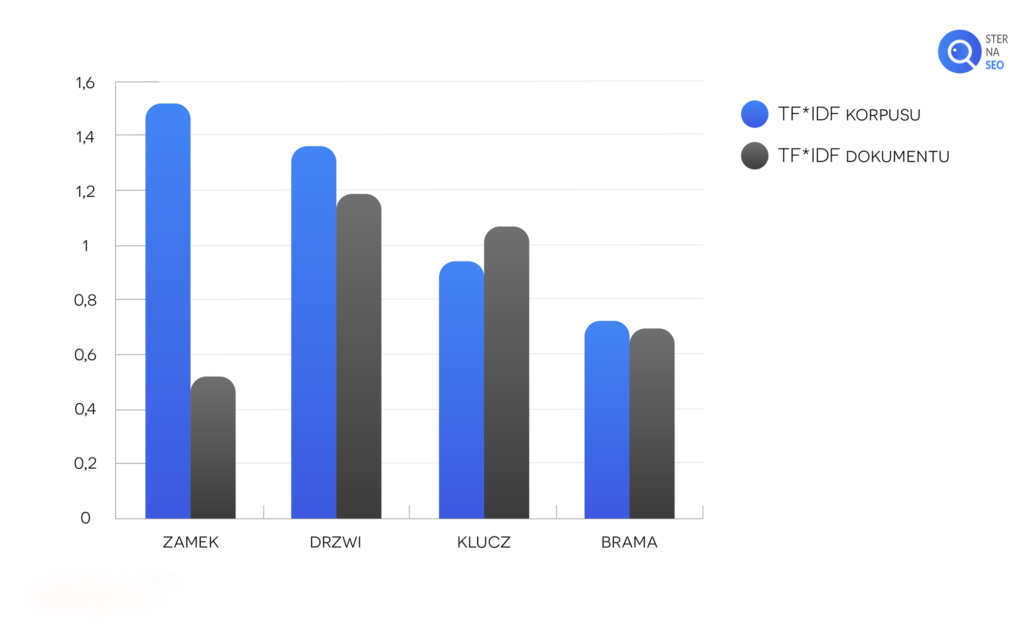
Na podstawie powyższego wykresu możemy ustalić, że słowo „zamek” występuje w badanych dokumentach częściej (w odniesieniu do liczby słów) niż w naszym tekście. Dzięki informacjom o TF*IDF możemy poprawić nasycenie naszego tekstu, a także dowiedzieć się, jakich wyrażeń powiązanych użyć, aby był on bardziej tematyczny.
Jak taki wykres może wyglądać w praktyce?
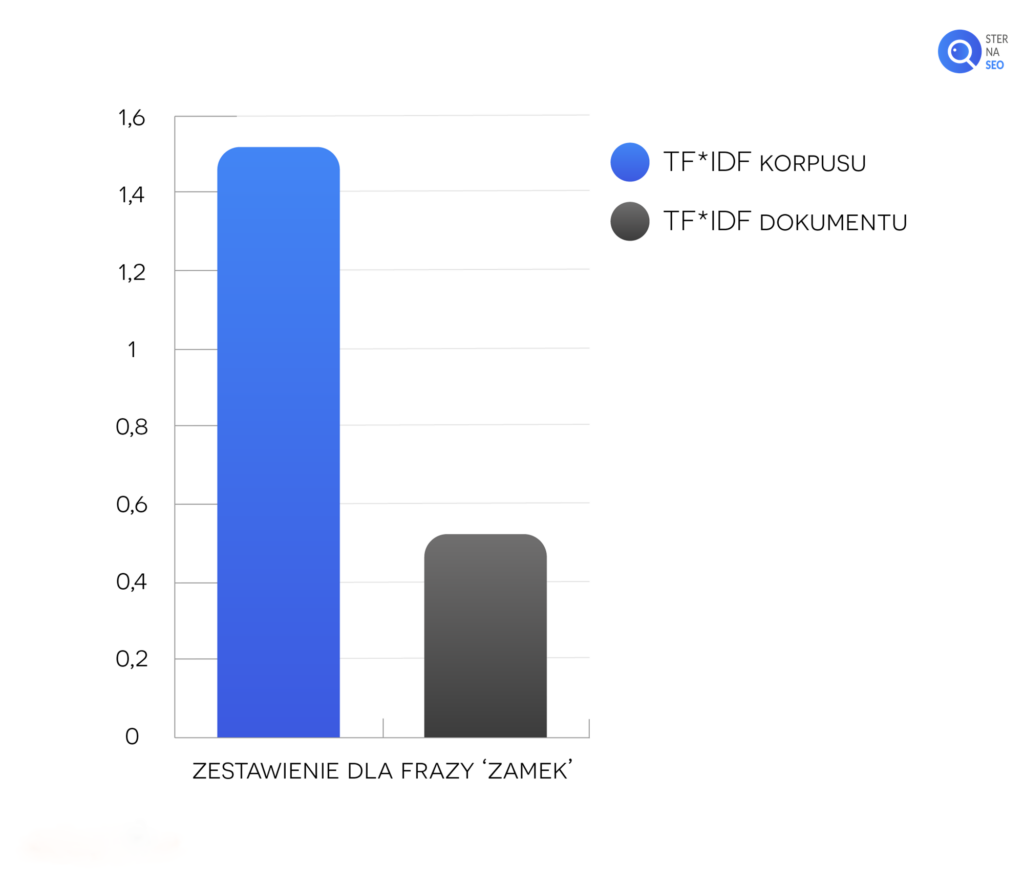
Tego typu wykresy mogą wyraźnie wskazać różnice między wagą danego wyrazu (częstotliwością jego występowania w odniesieniu do liczby wszystkich słów) w dokumencie a korpusie językowym (naszej bazie danych). W powyższym przykładzie już na pierwszy rzut oka widać, że TF*IDF – waga występowania słowa „zamek” jest znacznie niższa niż w innych dokumentach (uśredniając) w korpusie językowym, wartości fraz „brama” i „drzwi” również (lecz z mniejszą różnicą między dokumentem a bazą dokumentów). Waga słowa „klucz” natomiast jest wyższa w naszym tekście niż w korpusie.
Występowanie fraz powiązanych (wynikających z LSI) – „drzwi”, „klucz” oraz „brama” jasno wskazuje na to, że badany dokument dotyczy zamka jako mechanizmu otwierającego. Gdyby wartości tych trzech słów wyniosły 0, można byłoby przypuszczać, że jego tematyka dotyczy innego znaczenia „zamka”, szczególnie jeśli zawierałby wyrażenia powiązane z innym znaczeniem – np. „rozporek”, „kurtka”, „spodnie”, itp.
Jak można wykorzystać wynik TF*IDF w SEO Copywritingu i pozycjonowaniu witryny internetowej?
TF*IDF może być źródłem wielu cennych informacji dotyczących optymalizacji treści witryn internetowych w wyszukiwarkach pod kątem pozycjonowania. Ze względu na to, że otrzymany wynik zestawiany jest z wagą frazy w całym korpusie, można porównać nasycenie naszego tekstu do wartościowych, fachowych tekstów z naszej branży (np. z TOP5). Niewątpliwym atutem jest również fakt, że jako korpus może być wybrany dowolny zbiór dokumentów. W zależności od potrzeb, może być to TOP10 wyników wyszukiwania Google, TOP8 czy nawet trzy pierwsze rekordy w SERPach.
Co nam daje obliczenie wagi danej frazy z wagą występowania frazy w korpusie?
1. Jak już wcześniej wspomnieliśmy, możemy skontrolować, czy dane słowo na naszej podstronie występuje częściej, czy rzadziej niż w całym zbiorze dokumentów. Na tej podstawie można zoptymalizować nasycenie tak, aby dana podstrona potencjalnie mogła lepiej rankingować. Jest to niezwykle ważna wskazówka w SEO copywritingu.
2. Możemy sprawdzić tematyczność naszego tekstu poprzez kontrolę występowania poszczególnych wyrażeń powiązanych. Pamiętaj, że nawet tekst idealnie nasycony główną frazą może być mało tematyczny dla wyszukiwarek właśnie ze względu na to, że nie będzie zawierał innych słów kluczowych, które wskażą na konkretne znaczenie frazy.
Artykuł z idealnym nasyceniem słowa „zamek”, niezawierający wyrażeń powiązanych („drzwi”, „klucz”, itp.) nie będzie wyraźnie wskazywał na to, że dotyczy mechanizmów zamykających, a więc algorytmy Google mogą mieć problem z jego prawidłową oceną.
3. Jest to świetny sposób na optymalizację tekstu pod kątem mniej popularnych fraz (również z tzw. długiego ogona). Firmy pozycjonujące strony internetowe wiedzą, jak trudno jest uzyskać wysoką pozycję podstrony na często wykorzystywaną frazę. Dlatego też pozycjonowanie bardziej niszowych fraz może być strzałem w dziesiątkę.
4. Szybko zauważymy ewentualne przesycenie tekstu naszej strony internetowej – działania mające na celu masowe umieszczanie frazy na podstronie w żaden sposób nie pomoże w uzyskaniu wysokiego miejsca w SERPach wyszukiwarki.
Obliczanie TF*IDF dokumentu według podanego wyżej wzoru daje jasny obraz, jak nasz tekst prezentuje się na tle badanego korpusu językowego. Pozwala porównać nasycenie oraz tematyczność z innymi dokumentami z dowolnego zbioru, np. TOP10 wyszukiwarki.
Podsumowanie
Nigdy nie poznaliśmy dokładnych wytycznych i zasad działania algorytmów Google, które oceniają strony internetowe i decydują o ich pozycji w organicznych wynikach wyszukiwania. Posiadamy wyłącznie ogólne informacje, na których bazujemy, jak również własne doświadczenia, które pozwalają nam domyślać się, na jakie elementy zwracać szczególną uwagę podczas optymalizacji pod kątem SEO.
Pewne jest, że nasycenie fraz zawsze wpływało na pozycjonowanie. Poradnik dotyczący obliczania i wykorzystywania TF*IDF może odegrać ważną rolę w przygotowywaniu treści. Korzystanie z wyników TF*IDF pozwala sprawdzić, jaka częstotliwość występowania danych fraz jest preferowana w wybranym korpusie językowym, a także w jaki sposób zwiększyć tematyczność naszych treści.
Warto więc skorzystać z tej metody, aby stworzyć przyjazne oraz przystępne dla użytkownika treści SEO. A złota zasada mówi, że wszystko to, co jest przyjazne odbiorcom, jest też przyjazne dla algorytmów wyszukiwarek. O czym można się przekonać, choćby odwiedzając nasz blog o pozycjonowaniu, na którym znajduje się wiele artykułów i poradników z branży SEO.
Źródła: Semrush; Moz; Elephate; Google Patent; Medium











